В этом видео Энди Дженкинс рассказывает, как Google вычисляет дублированный контент и что нужно изменить в сайте, чтобы поисковые системы исправно индексировали страницы и не пеналили их за неоригинальное содержание.
Борьба с дублированным контентом вкупе с удвоением поискового трафика наверняка принесет ощутимые результаты.
Сейчас вы можете даже не подозревать о том, что Google или любая другая поисковая система накладывает санкции за дублированный контент на отдельные страницы вашего сайта. И узнаете вы об этом только тогда, когда ваши позиции в выдаче начнут медленно, но уверенно сползать вниз. Более того, если вы не предпримете никаких действий, Google может вообще удалить сайт из основного поиска, так что найти его можно будет только по названию домена.
Энди считает дублированный контент одной из основных проблем, с которыми сталкиваются как новички, так и опытные вебмастера. По его словам, около 75% его клиентов так или иначе пострадали от этой проблемы.
Как раз и навсегда избавиться от дублированного контента и обезопасить свой сайт на будущее
Особой зоной риска в плане дублированного контента можно считать Интернет-магазины, на которых продаются сотни и тысячи физических или информационных товаров различных торговых марок.
Дело в том, что вы можете создавать дубликаты страниц, даже не подозревая об этом. Однако не это главное. Главное, чтобы после просмотра этого видео, вы раз и навсегда избавили свой сайт от дублирующих страниц и тем самым только увеличили свой заработок в Интернете.
В начале видео Энди поясняет некоторые основные моменты:
1. Самым опасным типом дублированного контента является тот, который находится в пределах одного сайта.

Дубликаты с других сайтов тоже могут навредить вашему ресурсу, однако повторы внутри одного сайта обязательно сделают это.
2. Под контентом подразумевается текст, который видят посковые боты. При работе над дублированным контентом рисунки и даже текст внутри “alt”-тэга в расчет не берутся.
3. Залогом успеха, как и в случае с любым другим аспектом SEO, является тестирование. Энди дает базу, от которой вы будете отталкиваться во время работы со своим сайтом. Однако лишь тестируя и отслеживая результаты, вы сможете выжать из сайта максимум.
Что такое дублированный контент?
Это две или больше страниц на одном сайте, которые выглядят настолько похожими для поисковых машин, что те не считают нужным индексировать их.

Поисковый бот, по мнению Энди, реагирует примерно так: “Какого черта я буду загаживать свой винт одинаковыми страницами, да еще и с одного домена?” 🙂
То, что поисковая система отказывается индексировать такие страницы, чревато для вас неприятными последствиями:
- Страница не может попасть в выдачу по своему ключевому слову.
- Страница не может увеличить ссылочный вес страниц, на которые она ссылается, независимо от того, как выглядит якорь ссылки.
- Страница не может поднять PageRank других страниц.
Все вместе это приводит к тому, что сайт не может подняться в выдаче по ключевым запросам. Еще хуже, если поисковая система начинает считать дубликатами половину (или больше) страниц сайта. Во многих случаях это приводит к медленной, но уверенной смерти сайта, и тогда ваш сайт можно будет найти, только набрав в строке поиска название домена.
Волшебная пилюля
Чтобы решить проблему, нужно сначала взглянуть на нее глазами того, кто ее непосредственно создает, т.е. робота. Робот видите страницу несколько иначе, чем мы:
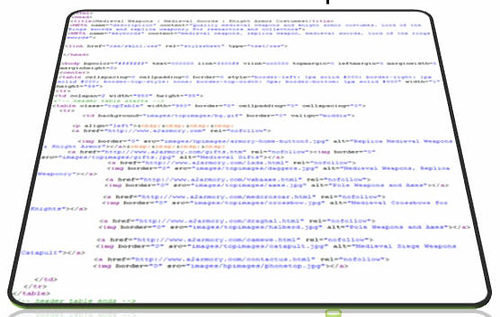
(Не волнуйтесь, колдовать над кодом вам практически не придется.)
Каждая страница сайта, в частности сайта Энди состоит из основных элементов:

где:
- Шапка сайта.
- Левая колонка.
- Правая колонка.
- Подвал.
- Наполнение (“content container”).
Вместе эти элементы составляют шаблон сайта. Каждый из них, кроме наполнения, повторяется на всех страницах и практически на всех страницах они выглядят одинаково. Единственное , что отличает страницы, — это их наполнение.
(В качестве модели для фотографии выступил сам Энди Дженкинс.)
Что видит на странице сайта человек?
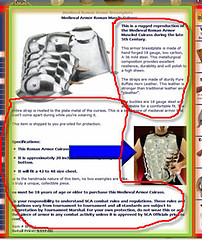
Попав на сайт, мы быстро привыкаем к шаблону и после этого видим только то, что на разных страницах выглядит иначе, т.е. мы видим наполнение и не замечаем структурных элементов страницы (выделено красным).

Кроме всего прочего, такая особенность восприятия позволяет сконцентрировать внимание посетителя на вашем сообщении (в данном случае на описании кольчуги).
Что видит на странице сайта робот?
Поисковые боты в отличие от человека не умеют запоминать повторяющиеся элементы сайта, поэтому при оценке новой страницы на предмет дублирования контента робот учитывает текстовое содержимое всех элементов страницы.

Если две страницы выглядят так:
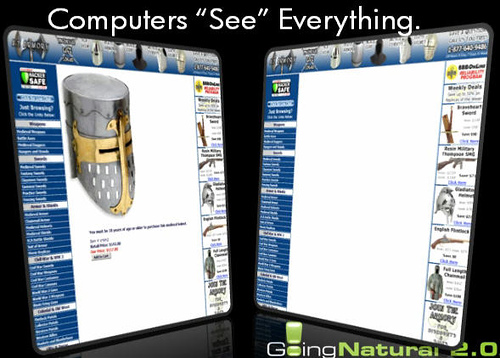
то человек сможет заметить разницу. А робот нет. Он просто примет те пару-тройку строчек текста, которые отличают страницы, за погрешность и даст новой странице однозначный диагноз: “Дублированный Контент”.
Решение проблемы
Итак, мы имеем следующее:
- робот видит всю страницу;
- робот считает каждое слово на странице
- Web-дизайнеры, создавая страницу, часто думают о людях и забывают о роботах
Однако именно робот решает, какое место займет страница в выдаче и будет ли она проиндексирована вообще, следовательно, вы должны дать ему то, что он от вас хочет.
Теперь по пунктам:
1. Подсчитайте количество слов в шаблоне страницы (все элементы кроме наполнения).
Для этого выделите весь текст на странице (Правка –> Выделить Все (Ctrl + A)) и скопируйте его (Правка –> Копировать (Ctrl + C)) в Word. Теперь воспользуйтесь меню Сервис –> Cтатистика и посмотрите, сколько слов содержит ваш шаблон.
Так, например, шаблон Энди содержит всего 220 с лишним слов. Как ему это удалось? Об этом немного позже.
А пока запишите или запомните цифру, которую вы только что узнали.

Ваша задача — создать такое текстовое наполнение, чтобы число слов в нем превышало число слов в элементах шаблона.

Благодаря этому простому действию страница станет непохожей на другие, и шансы того, что поисковый робот признает ее дубликатом, снизятся до минимума.
2. Измените заголовок страницы (содержимое тэга <title>). У вас не должно быть двух страниц с одинаковыми заголовками.
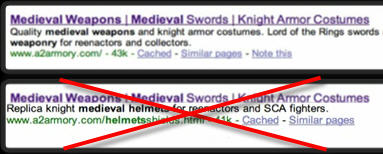
Это единственный раз, когда вам придется немного поработать с кодом.
Важно: Как вы считаете, следующие заголовки одинаковы или нет?

Для человека да, а вот для машины — совсем не обязательно.
В SEO есть такое понятие как стоп-слова. Это слова или короткие фразы, которые поисковые системы не принимают во внимание при определении релевантности и ранжировании страниц.
Какое это имеет отношение к вам? Если вы сделали контент страниц уникальным, но поисковик упорно отказывается индексировать страницу, проблема может заключаться в ее заголовке, а именно в стоп-словах, которые он содержит. Если заголовки страниц отличаются только стоп-словами, можете считать, что вы нашли источник своих бед. Вот их список.

Этот же список вы можете посмотреть в блоге Stompernet. Еще лучше, скопируйте его на жесткий диск и распечатайте.
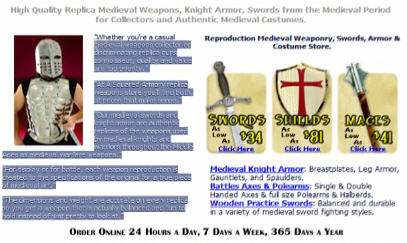
3. Где это возможно, замените текст рисунком.
Вот почему у Энди так мало слов в шаблоне. Значительная часть текста изображена в виде рисунков, которые может “прочитать” человек, но не может машина. Посмотрите на рисунок.

Правильно, это текст. Но Энди не может выделить его. Значит, что это? Правильно, рисунок. Вот так Энди “обманывает” поисковых роботов и уменьшает количество слов в шаблоне. Робот не может ни увидеть, ни понять, ни посчитать эти слова.
Еще один пример: сайт, посвященный жилищной ипотеке. Законодательство США требует, чтобы на каждой странице сайта компании, занимающейся ипотекой, висел огромадный дисклеймер вроде того, что на картинке.
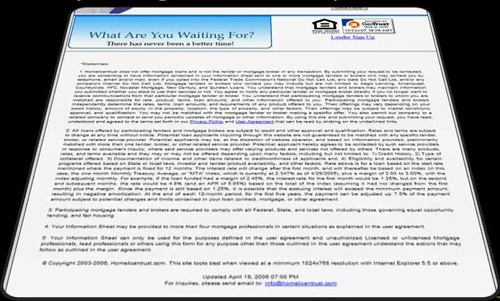
Это 800 слов абсолютно идентичного текста на каждой странице. Естественно, его лучше заменить рисунком. Но…
Дисклеймер обязан присутствовать на сайте в виде текста, так чтобы его могли обнаружить поисковые боты, и чтобы посетитель мог при желании скопировать его себе на компьютер. В этом случае вы должны создать отдельную страничку и поместить туда текст. А чтобы этот текст нашел посетитель (бот его найдет сам), к каждому графическому изображению дисклеймера прикрепите ALT-тэг с таким содержанием.

И волки сыты, и овцы целы.
SEO миф
В заключительной части видео Энди развенчивает миф о том, что вес ссылок с других сайтов, сколько-нибудь выше, чем вес ссылок с внутренних страниц сайтов.

Энди заявляет, что при прочих равных условиях их вес одинаков. (Кому-кому, а Энди верить можно. ;)) Именно поэтому вам нужно приложить максимум усилий, чтобы поисковый робот не посчитал ваши внутренние страницы дубликатами главной. Вполне вероятно, что у вас уже есть значительное количество страниц с дублированным контентом, которые можно вернуть в индекс прямо сейчас. И стоит вам это сделать, как страницы (в том числе и главная) практически сразу начнут подниматься в выдаче. А вместе с главной начнут подниматься и второстепенные (см. перевод предыдущего видео).
Оставайтесь на связи! Это далеко не последнее видео от Энди Дженкинса.
п.с. Надеюсь, вам понравилась эта статья. Если да, буду очень признателен, если вы поспособствуете ее социализации. Напишите комментарий, поставьте закладку, проголосуйте на News2.0, сообщите о статье в своем блоге, скопируйте ее к себе в блог (с сохранением ссылок).
Заранее благодарен!
Записи по теме:
- Как сравнить результаты выдачи разных поисковых систем
- SEO и модификаторы ключевых слов
- Быстрое индексирование крупных сайтов
- Изучение обратных ссылок конкурентов

Работа, на которую не нужно устраиваться.
http://www.rabota21veka.com
Читал статью раньше, очень понравилась. Сегодня хотел перечитать, так сказать вернуться к “истокам”, но не смог. Куда-то подевались все картинки 🙁
роботы тоже не дураки, насколько я знаю, с картинки они могут читать текст (гугл точно)
Действительно, проблема дублированного контента очень актуальна.
Спасибо за статью – очень познавательна для начинающего блоггера)))
И у меня ни одна картинка не отображается.
По делу:
Есть спецы, которые эту фишку автоматизируют?
Похоже моего сайта это на все сто коснулось((( Спасибо за материал!!! Сейчас не видно уже иллюстрирующего материала, только следы от Флика. Он будет обновлен?
Спасибо за статью – было полезно с ней ознакомится. Удивило, что вес ссылок с внешних и внутренних страниц одинаков.
Лично сам столкнулся с этой проблемой. Например CMS плодит несколько ссылок на один и тот же контент, открывая его на ГЛАВНОЙ и в РАЗДЕЛЕ. Ссылки в этом случае разные и ПС индексирует эти страницЫ!! Затем… я получаю по шапке за дублированный контент и за то, что пытался обмануть ПС. А уж если отправить автоматически созданный sitemap.xml – крышка! Страниц в нем в пять раз больше чем “контентных”. Убрал клонов с помощью canonical – полез в СЕРПе вверх.
куда делись картинки?
Уважаемый автор
По моему, у Вас проблемы с отображением сайа?
Очень интересный блог много полезного, но у меня тоже картинки не отображаются, поэтому половину из написаного не поняла.Я думала у себя на сайте seomanka.com все ссылочные кнопки меню закрыть тегом ноиндекс, а тут вы говорите что гугл этот тег не учитывает…Совсем запуталась.
Пост очень полезный, но отсутствие скринов(как я понял это временная проблема) намного усложняет процесс воспириятия информации.
Спасибо за статью, для начинающих она очень полезна
Я nofollow ставлю на магазин
Картинки не отображаются, без них не всё ясно из написанного.
Не совсем так. Гугл может выбирать из дублированных страниц одну наиболее релевантную (на его взгляд) страницу (например анонс новости, подробнее, версия для печати, версия с комментариями). Он не всегда тупо отказываться от индексации…
Класная статья
А ведь может случиться, что автора в плагиаторы запишут и опустят, обидно будет. 🙁
Всё конечно интересно, я даже занёс сайт в закладки – буду иногда почитывать, но почему я не вижу фото?!?