Содержание статьи
- Понятие Google RankBrain
- Hummingbird (Колибри)
- Движение от «строк символов» к «объектам»
- Комплексные запросы и их влияние на выдачу
- Примеры работы алгоритма
Понятие Google RankBrain
RankBrain – это новая самообучающаяся система построения выдачи от Google, которая ищет релевантные ответы на запрос пользователя, основываясь на таких факторах, как история запросов, поведение пользователей, контекст страниц (узнать больше об LSI технологии индексирования).
В конце октября появились новости о новой самообучающейся системе Google RankBrain, которая, вместе с другими факторами ранжирования, помогает определить наиболее релевантные страницы для поисковых запросов пользователей.
Если быть конкретнее, то RankBrain обрабатывает и уточняет запросы, используя шаблоны распознавания для сложных и неоднозначных (двусмысленных) ключевых фраз и определяя их в те или иные тематики.
Это позволяет Гуглу показывать более качественные результаты поиска, особенно когда речь заходит о сотнях миллионов запросов в день. Сотрудники поисковой системы отметили, что RankBrain – это один из самых важных факторов ранжирования из тех, которые учитывает алгоритм.
RankBrain – это один из сотен сигналов, который определяет, какие результаты должны появиться в выдаче и как они будут ранжироваться. Он является попыткой усовершенствовать результаты поиска, базирующегося на технологии Графа Знаний и объектного поиска:
Итак, что представляет собой объективный поиск? Как он работает вместе с RankBrain и в каком направлении шагает Google? Чтобы понять это, необходимо вернуться на несколько лет назад.
Hummingbird (Колибри)
Запуск этого алгоритма был радикальной переменой. Это была реконструкция того, как Гугл обрабатывал органические запросы: от поиска строк из символов до нахождения самих объектов, для которых определено конкретное значение, свойства и связи с другими объектами.
Как появился «Колибри»? Новый алгоритм родился из попыток разработчиков встроить семантический поиск в поисковый движок Гугла. Другими словами, они хотели сделать самообучающуюся машину, которая могла бы понимать естественный язык человека (технология NLP). Предполагалось, что поисковик будет понимать, что вы имеете в виду, когда печатаете свой запрос.
Цель семантического поиска – улучшить точность результата посредством распознавания намерений пользователя и контекстуального значения терминов, чтобы генерировать более релевантные результаты. Системы семантического поиска учитывают различные параметры (включая контекст, цели пользователя, вариации слов, синонимы, обобщённые и узкотематические запросы), чтобы давать наиболее точные ответы.
Прошло два года, однако каждый, кто использует Google, понимает, что мечта семантического поиска ещё не воплощена в жизнь. Хотя некоторые попытки в этом направлении уже делаются. Например, используются базы данных для определения и объединения объектов в группы по значению. Тем не менее, семантический движок должен понимать, как контекст влияет на слова, и быть способным определять и толковать их значение.
Google пока не умеет понимать естественный (человеческий) язык, хотя и способен воспринимать известные объекты и отношения через определения.
Конечно, поисковик может выучить множество понятий и отношений через некоторое время, если достаточно много людей ищут какие-то совокупности терминов. Здесь-то и вступает в работу самообучающаяся машина (RankBrain). На основе полученного опыта она пытается сделать наиболее релевантное предположение при формировании выдачи.
Итак, по определению Google – это не семантический поисковый движок. Тогда какой он?
Движение от «строк символов» к «объектам»
Поисковая система сегодня имеет превосходные способности к показу конкретной информации. Нужен прогноз погоды? Сведения о пробках? Обзоры ресторанов? Гугл может предоставить эту информацию, избавляя от необходимости посещать сторонние сайты. От просто даёт ответ в начале страницы выдачи. Такое возможно благодаря Графу Знаний.
Движение от «строк» к «объектам» отлично помогает, когда нужно найти ответ на вопросы, начинающиеся с «Кто», «Что», «Где», «Когда», «Почему» и «Как». Более того, руководствуясь информацией из Графа Знаний, Гугл способен давать пользователям ту информацию, о которой они даже не знали, но которая могла бы быть им полезна.
Тем не менее, этот скачок в сторону «объектов» имеет недостатки. Хотя ПС хороша в предоставлении конкретной, основанной на базах данных, информации, она пока ещё не так успешна в поиске максимально релевантных ответов для сложных составных запросов. Такие запросы часто состоят из терминов, которые слабо связаны между собой. Гуглу сложно объединить их в один «объект».
В результате, когда вы задаёте в поиске некоторую совокупность сложных терминов, вероятнее всего, что вы получите всего несколько релевантных результатов, причём степень этой релевантности будет не очень высокой. В большинстве своём, выдача представляет собой набор случайных вариантов, но никак не прямые ответы. Но почему так происходит?
Комплексные запросы и их влияние на выдачу
Как мы уже говорили, Гуглу сложно подобрать подходящие ответы в запросах, в которых есть несколько плохо связанных между собой терминов. ПС не в состоянии понять и установить взаимосвязи. В таком случае, технология RankBrain делает предположение об отношениях между этими терминами, угадывает их.
Попробуйте напечатать составной запрос, используя выпадающий список вариантов. Выберите наиболее подходящий из них. Вы увидите, что запросы, предложенные самим Google, дают более точные результаты в выдаче. Всё потому, что сами объекты в запросе и связи между ними известны поисковику.
К слову, что подразумевается под словом «объект»?
Это существительные: люди/места/вещи/идеи и пр. Их значение определено в базах данных, к которым обращается Гугл. ПС действует как огромная цифровая энциклопедия. Тем не менее, если два объекта в ней не связаны между собой, машина испытывает трудности в понимании запроса пользователя. Она просто делает предположение.
Примеры работы алгоритма
- Введём запрос “Iced tea, Lemon, Glass” (Ледяной чай, лимон, стакан). Он состоит из объектов, которые имеют понятную взаимосвязь. Поисковик выдаст нам массу высоко релевантных результатов.
- Теперь изменим его: “Iced Tea, Rooibos, Glass” (Ледяной чай, ройбос, стакан). Наблюдается всё ещё достаточная релевантность, но она уже снижается. Почему? Потому что Ройбос редко используется для приготовления ледяного чая.
- “Iced Tea, Goji, Glass” (Ледяной чай, Годжи, стакан). Наблюдаем частичную релевантность. Некоторые объекты выпадают. Гугл в лёгком замешательстве.
- “Iced tea, Dissolved Sugar, Glass” (Ледяной чай, растворённый сахар, стакан). В выдачу попадают не только страницы с рецептами чая, но и с описанием химических процессов.
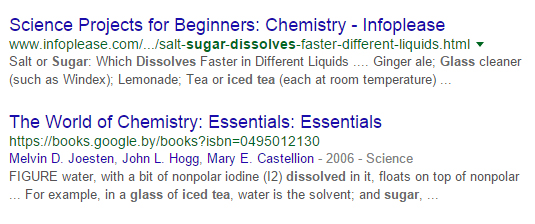
- Но, если мы воспользуемся выпадающей подсказкой Google и введём “Glass of sugar iced tea”, то опять получим очень качественную выдачу, отвечающую на наш вопрос.
Гугл пытается перевести слова, которые встречаются на страницах, в «объекты», которые что-то означают и имеют какие-то свойства. Это то, что обычно делает человеческий мозг, но в случае компьютера это называется «искусственный интеллект».
Это сложная задача, но работа уже ведётся. «Google строит своё собственное понимание того, что представляют собой те или иные объекты и что людям следует о них знать», – отмечает инженер-программист компании Amit Singhal.

С чаем конечно загнули лихо-)) Гугл в ступоре
Неплохо таки) Автору спасибо за проделанный труд, читала с удовольствием.
Хорошая статья, спасибо.
Неплохо!
Так что же он из себя представляет? Как он работает вместе с новым сигналом ранжирования? Куда движется Google? Чтобы понять это, нужно отправиться в прошлое.
Да хорошая статья теперь немного знаю о РангеМозга
Интересная информация. Надеюсь в скором времени поисковики улучшат выдачу и понимание запросов.
Движение в сторону использования искусственного интеллекта набирает обороты и было бы удивительно, если бы гугл не использовал его в ранжировании результатов поиска
Как именно на практике работать с данным алгоритмом и усилить влияние на позиции сайта?
По сравнению с системой ранжирования яндекс, по мне так, гугл слабоват. Яша – революционер, гугл – консерватор.